
作者|贾少华
1 理论介绍

图1. 传统LDA模型
LDA模型意在寻求一篇文档中蕴含的潜在主题,其中对于潜在主题的个数一般通过困惑度亦或是对数似然值来确定。通常,一篇文档有包含多个部分,每个部分有N多词构成,也就是说由N多词构成一个个主题,而后由一个个主题构成了一篇文档。
对于文档集D中的每个文档w,LDA假设了以下的生成过程:
1)
2)
3)对于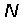 个单词中的每一个单词
个单词中的每一个单词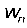 :
:
(a)
(b)从 中选择一个单词
中选择一个单词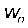 ;
;
LDA模型中,需要估计的参数有两个,分别为θ和φ,即文档-主题概分布与主题-词概率分布。因使用EM对θ和φ进行参数估计的方法难以通过代码实现,故而在后续的模型学习与实现中,通常采用Gibbs抽样对这两个参数进行值的估计。
2 数据准备
此次Demo实验选取部分Yelp电商评论中的文本部分,其中评论有真有假,分别对真实评论和虚假评论进行主题抽取。其中表一展示的是一条原始的评论数据集和对应的清洗干净的数据集。
表1原始数据与干净数据

当数据量较小的时候,LDA抽取的主题代表性不强,因此此处为了扩大建模的单词量,将真实评论合并为一个文档,虚假评论合并为一个文档,分别使用LDA对其进行建模,主题抽取结果如表2,表3所示。
表2 真实评论主题抽取


表3 虚假评论主题抽取

附录:代码(python3.6,jupyter notebook)





-END-
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

评论(0)